Animated Image

Animated Image

Animated Image




We present ReBotNet, a video architecture designed to swiftly enhance live streams and video conferences in real-time.
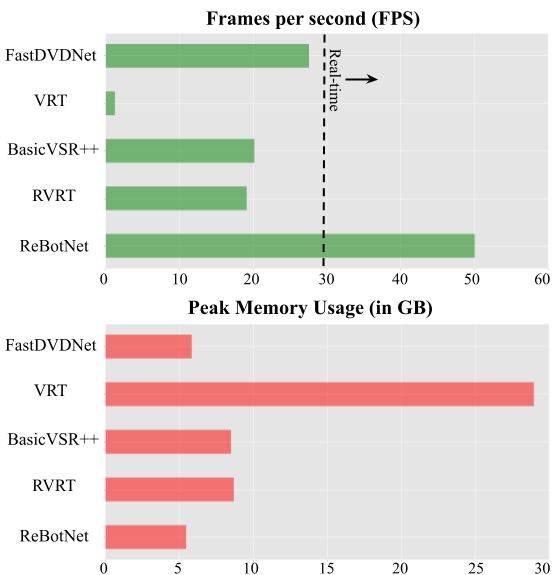
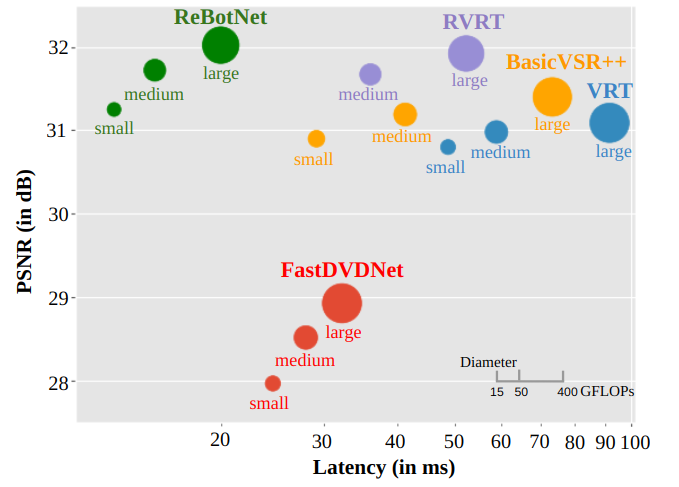
Most video restoration networks are slow, have high computational load, and can't be used for real-time video enhancement. In this work, we design an efficient and fast framework to perform real-time video enhancement for practical use-cases like live video calls and video streams. Our proposed method, called Recurrent Bottleneck Mixer Network (ReBotNet), employs a dual-branch framework. The first branch learns spatio-temporal features by tokenizing the input frames along the spatial and temporal dimensions using a ConvNext-based encoder and processing these abstract tokens using a bottleneck mixer. To further improve temporal consistency, the second branch employs a mixer directly on tokens extracted from individual frames. A common decoder then merges the features form the two branches to predict the enhanced frame. In addition, we propose a recurrent training approach where the last frame's prediction is leveraged to efficiently enhance the current frame while improving temporal consistency. To evaluate our method, we curate two new datasets that emulate real-world video call and streaming scenarios, and show extensive results on multiple datasets where ReBotNet outperforms existing approaches with lower computations, reduced memory requirements, and faster inference time.


|

|
@misc{valanarasu2023rebotnet,
title={ReBotNet: Fast Real-time Video Enhancement},
author={Jeya Maria Jose Valanarasu and Rahul Garg and Andeep Toor and Xin Tong and Weijuan Xi and Andreas Lugmayr and Vishal M. Patel and Anne Menini},
year={2023},
eprint={2303.13504},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
